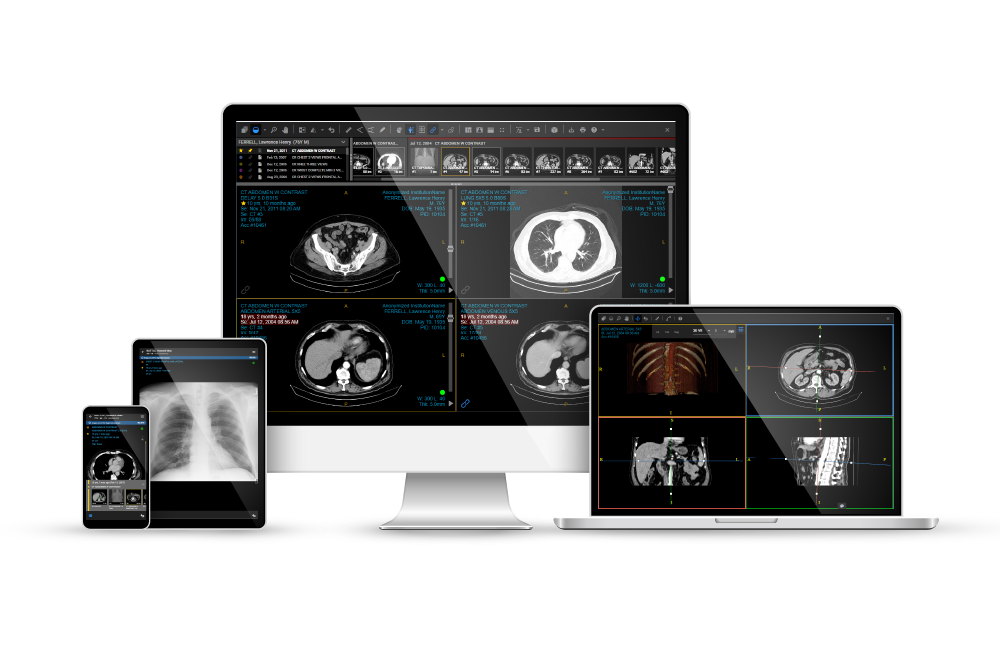
Our partnership with Life Image allows us to solve some of the toughest technical challenges in interoperability so that medical image exchange and related data only takes moments. Our Image Exchange network allows healthcare professionals to turn data into information, enabling them to learn from it, make better informed clinical decisions, improve the patient experience, and ultimately make new discoveries that will improve patient outcomes. Bringing 10,000 facilities, 160,000 U.S. providers, 58,000 global clinics and millions of patients into our scope of work, our partnership with Life Image advances Intelerad’s mission of positively impacting global human health.
Establishing the Clear Medical Image Exchange
Market Leader and Path to a Global Open Image Exchange Network
Intelerad, a leading global provider of enterprise imaging solutions, has combined with Life Image, one of the largest image exchange networks of curated clinical and imaging data, creating the largest medical image exchange network in the world and laying the ground work for the elimination of costly CDs as the primary means of image transfer.
This new partnership significantly expands the combined company’s ability to enable distributed radiology reading, collaborative care solutions, and advanced life science research in multiple markets to improve the health of populations.